With the rapid advancement of remote sensing technologies, the availability of large-scale satellite image datasets has grown exponentially. These datasets contain invaluable information for various applications, including environmental monitoring, urban planning, and disaster management. However, extracting specific categories of objects, such as identifying all images which are similar to a sepcific query image within a dataset of thousands or millions or even billions of samples, presents a significant challenge for human analyst. ships within a dataset of one million samples, presents a significant challenge due to the sheer volume of data and the complexity of manual analysis.
Solution
This task, which is overwhelming for human analysts, can be efficiently addressed using vector search techniques. By leveraging deep learning models to transform images into high-dimensional vectors and utilizing various models such as classification, segmentation, etc, we can use their last layer features and employ nearest neighbor search algorithms to quickly and accurately retrieve relevant images based on their content or semantic meaning.
For instance, you find and interesting shape in your dataset and you want to figure out if there is any similar image in your dataset or not? To do so, you can use that image as a search query to find the similar images.
Good to know
- I just fine-tuned ResNet50 on AID dataset, we can train more architectures on different datasets and benchmark them.
- By fine-tuning on a large-scale dataset, the accuracy significantly improves.
- It's not a production-level (or even near-production-level) solution, so there is plenty of room for improvement in both speed and accuracy.
- We can use vector databases such as Weaviate or Redis instead of a simple Python list.
- It's good to dig into the datasets first and then judge the performance of the model.
- You can find the code on Github
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torchvision import models, transforms, utils
from torch.utils.data import Dataset, DataLoader, random_split
from skimage import io, transform
from sklearn.neighbors import NearestNeighbors
from sklearn.metrics import confusion_matrix, accuracy_score
import os
import glob
import random
from PIL import Image
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
Datasets
AID
To Do
- Dataset Details
class AID(Dataset):
def __init__(self, root_dir):
self.label_map = {}
self.info = []
i = 0
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith((".jpg", ".tif", ".png", "jpeg")):
file_path = os.path.join(root, file)
label = root.split('/')[-1]
self.info.append((file_path, label.lower()))
if label.lower() not in self.label_map:
self.label_map[label.lower()] = i
i += 1
random.shuffle(self.info)
self.transform = transform
def map_labels(self, label):
return self.label_map[label]
def __len__(self):
return len(self.info)
def __getitem__(self, idx):
img_path, label = self.info[idx]
label = self.map_labels(label.lower())
img = io.imread(img_path)[:,:,:3]
img = img / 255.
img = torch.tensor(img, dtype=torch.float32)
return img, label, img_path
dataset = AID('datasets/AID')
label_map = dataset.label_map
class_map = {v: k for k, v in label_map.items()}
classes = [v for k,v in class_map.items()]
rows, columns = 2, 5
fig, axs = plt.subplots(rows, columns, figsize=(21, 8), squeeze=True)
n = 0
for i in range(rows):
for j in range(columns):
img, label, _ = dataset[n]
clss = class_map[label]
axs[i][j].imshow(img)
axs[i][j].set_title(clss)
n += 1
plt.show()

FAIR1M
class FAIR1M(Dataset):
def __init__(self, root_dir, transform=None):
self.label_map = {
'ship': 0,
'airplane': 1,
'neighborhood': 2,
}
self.info = []
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith((".jpg", ".tif", ".png", "jpeg")):
file_path = os.path.join(root, file)
label = root.split('/')[-1]
self.info.append((file_path, label.lower()))
random.shuffle(self.info)
self.transform = transform
def map_labels(self, label):
return self.label_map[label]
def __len__(self):
return len(self.info)
def __getitem__(self, idx):
img_path, label = self.info[idx]
label = self.map_labels(label.lower())
img = io.imread(img_path)[:,:,:3]
img = img / 255.
img = torch.tensor(img, dtype=torch.float32)
return img, label, img_path
dataset = FAIR1M('datasets/FAIR1M_partial')
class_map = {
0: 'ship',
1: 'airplane',
2: 'neighborhood',
}
classes = [v for k,v in class_map.items()]
classes
['ship', 'airplane', 'neighborhood']
rows, columns = 2, 5
fig, axs = plt.subplots(rows, columns, figsize=(21, 8), squeeze=True)
n = 0
for i in range(rows):
for j in range(columns):
img, label, _ = dataset[n]
clss = class_map[label]
axs[i][j].imshow(img)
axs[i][j].set_title(clss)
n += 1
plt.show()
RESISC45
class RESISC45(Dataset):
def __init__(self, root_dir, transform=None):
self.label_map = {
'ship': 0,
'airplane': 1,
'bridge': 2,
}
self.info = []
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith((".jpg", ".tif", ".png", "jpeg")):
file_path = os.path.join(root, file)
label = root.split('/')[-1]
self.info.append((file_path, label))
random.shuffle(self.info)
self.transform = transform
def map_labels(self, label):
return self.label_map[label]
def __len__(self):
return len(self.info)
def __getitem__(self, idx):
img_path, label = self.info[idx]
label = self.map_labels(label.lower())
img = io.imread(img_path)[:,:,:3]
img = img / 255.
img = torch.tensor(img, dtype=torch.float32)
return img, label, img_path
dataset = RESISC45('datasets/RESISC45_partial')
class_map = {
0: 'ship',
1: 'airplane',
2: 'bridge',
}
classes = [v for k,v in class_map.items()]
classes
['ship', 'airplane', 'bridge']
rows, columns = 2, 5
fig, axs = plt.subplots(rows, columns, figsize=(21, 8), squeeze=True)
n = 0
for i in range(rows):
for j in range(columns):
img, label, _ = dataset[n]
clss = class_map[label]
axs[i][j].imshow(img)
axs[i][j].set_title(clss)
n += 1
plt.show()
Sentinel-2 ship
class SS2(Dataset):
def __init__(self, root_dir, transform=None):
self.label_map = {
'ship': 0,
'noship': 1,
}
self.info = []
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith((".jpg", ".tif", ".png", "jpeg")):
file_path = os.path.join(root, file)
label = root.split('/')[-1]
self.info.append((file_path, label))
random.shuffle(self.info)
self.transform = transform
def map_labels(self, label):
return self.label_map[label]
def __len__(self):
return len(self.info)
def __getitem__(self, idx):
img_path, label = self.info[idx]
label = self.map_labels(label.lower())
img = io.imread(img_path)[:,:,:3]
img = img / 255.
img = torch.tensor(img, dtype=torch.float32)
return img, label, img_path
dataset = SS2('datasets/Sentinel2_partial')
class_map = {
0: 'ship',
1: 'noship',
}
classes = [v for k,v in class_map.items()]
classes
['ship', 'noship']
rows, columns = 2, 5
fig, axs = plt.subplots(rows, columns, figsize=(21, 8), squeeze=True)
n = 0
for i in range(rows):
for j in range(columns):
img, label, _ = dataset[n]
clss = class_map[label]
axs[i][j].imshow(img)
axs[i][j].set_title(clss)
n += 1
plt.show()
Models
- https://pytorch.org/vision/stable/models.html
- https://pytorch.org/vision/main/models
- load your neural netwrok for feature extraction
To Do
- Use fine-tuned weights
- Use different architectures for this task and compare their infernce speed and accuracy.
weights = ['IMAGENET1K_V1', 'IMAGENET1K_V2', 'IMAGENET1K_SWAG_E2E_V1', 'IMAGENET1K_SWAG_E2E_V1', 'IMAGENET1K_SWAG_LINEAR_V1']
This is a simple way to load a pre-trained model using PyTorch
model = torch.hub.load("pytorch/vision", 'resnet50', weights="IMAGENET1K_V2")
Swin
Pre-trained on ImageNet
# Swin
from torchvision.models import swin_v2_b, Swin_B_Weights
model = models.swin_v2_b(weights=Swin_B_Weights).to(device).eval()
total_params = '{:,}'.format(sum(p.numel() for p in model.parameters()))
total_params
model
ResNet
Pre-trained on ImageNet
# model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2).to(device).eval()
# model = models.resnet50(pretrained=True)
Fine-tuned on AID
model = models.resnet50(pretrained=False)
/home/amir/miniconda3/envs/faiss/lib/python3.11/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/amir/miniconda3/envs/faiss/lib/python3.11/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or None for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing weights=None.
warnings.warn(msg)
model
Modify the last layer based on your fine-tuned weights
num_classes = 17 # AID
# num_classes = 43 # BigEarthNet
model.fc = torch.nn.Linear(model.fc.in_features, num_classes)
checkpoint = torch.load('weights/aid_multilabel_scratch_resnet50.pth', map_location=torch.device('cpu'))
state_dict = checkpoint['state_dict']
model.load_state_dict(state_dict)
model.to(device).eval()
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=17, bias=True)
)
Using this module, we can extract features from the last layer of our network, to use it as our feature extractor for our vector database
class ResNetFeatures(torch.nn.Module):
def __init__(self, original_model):
super(ResNetFeatures, self).__init__()
self.features = torch.nn.Sequential(*list(original_model.children())[:-1]) # all layers except the final FC layer
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
return x
# Create an instance of the new model
model = ResNetFeatures(model).to(device).eval()
for key in state_dict.keys():
print(key)
Number of model parameters
total_params = '{:,}'.format(sum(p.numel() for p in model.parameters()))
total_params
'23,508,032'
RegNet
# RegNet
model = models.regnet_y_400mf(pretrained=True).to(device).eval()
total_params = '{:,}'.format(sum(p.numel() for p in model.parameters()))
total_params
model
Metrics
To Do
- What metrics for CBIR?
def accuracy(query_label, neighbors, labels):
''' A simple function to calculate the accuracy for 1 sample @ K'''
t, f = 0, 0
for i in neighbors:
if query_label == labels[i]:
t += 1
else:
f += 1
return '{:.1%}'.format(t / (t + f))
Vector Database
Here we use our feature extractor to convert all of our images to a (1, 2048) vector and store them in our vector database (a python list in here) and perform our NN search.
Of course it's not implemented for production level use, but we can scale it using Vector Database such as Weaviate or Pinecone, etc. We can also use simpler implementation with FAISS library for our vector database and NN search.
features = []
image_paths = []
labels = []
# Change the first line according to the dataset you want to use
for x, y, img_path in dataset:
img = x.permute(2, 0, 1).unsqueeze(0)
with torch.no_grad():
feature = model(img.to(device)).detach().cpu().numpy()
features.append(feature)
image_paths.append(img_path)
labels.append(y)
features = np.concatenate(features, axis=0)
features.shape
(10000, 2048)
Swin
- took
ResNet
- Took 4m 20s for AID on NVIDIA 3060
NN Search
id = random.randint(0, len(dataset))
img, label, img_path = dataset[id]
img = img.permute(2, 0, 1).unsqueeze(0)
query_image_path = img_path
query_label = label
with torch.no_grad():
query_feature = model(img.to(device)).detach().cpu().numpy()
k = 20
neigh = NearestNeighbors(n_neighbors=k, algorithm='brute')
neigh.fit(features)
distances, indices = neigh.kneighbors(query_feature)
# Plot query image
query_image = Image.open(query_image_path)
print(f'Accuracy for this sample @ k = {k}: {accuracy(query_label, indices[0], labels)}')
rows, columns = 4, 5
fig, axs = plt.subplots(rows, columns, figsize=(34, 21))
n = 0
for i in range(rows):
for j in range(columns):
if (i == 0) and (j == 0):
axs[0][0].imshow(query_image)
axs[0][0].set_title(f'Query: {class_map[query_label]}')
else:
axs[i][j].imshow(Image.open(image_paths[indices[0][n+1]]))
axs[i][j].set_title(f'NN {n+1}: {class_map[labels[indices[0][n+1]]]}')
n += 1
Accuracy for this sample @ k = 20: 100.0%
Evaluation
We used the AID dataset for both training and inference
def compute_confusion_matrix_and_accuracy(dataset, model, device, features, labels, ks):
# Initialize a dictionary to hold confusion matrices and accuracies for different k
results = {k: {'confusion_matrix': None, 'accuracy': None, 'per_class_accuracy': None, 'confusion_matrix_accuracy': None} for k in ks}
# Initialize the NearestNeighbors model
neigh = NearestNeighbors(n_neighbors=max(ks), algorithm='brute')
neigh.fit(features)
# Prepare ground truth and predicted labels for confusion matrix calculation
all_true_labels = []
all_pred_labels = {k: [] for k in ks}
for i in range(len(dataset)):
img, label, _ = dataset[i]
img = img.permute(2, 0, 1).unsqueeze(0)
with torch.no_grad():
query_feature = model(img.to(device)).detach().cpu().numpy()
distances, indices = neigh.kneighbors(query_feature)
true_label = labels[i]
all_true_labels.append(true_label)
for k in ks:
neighbors = indices[0][:k]
predicted_label = np.bincount([labels[n] for n in neighbors]).argmax()
all_pred_labels[k].append(predicted_label)
# Calculate confusion matrices and accuracies for each k
for k in ks:
cm = confusion_matrix(all_true_labels, all_pred_labels[k])
acc = accuracy_score(all_true_labels, all_pred_labels[k])
results[k]['confusion_matrix'] = cm
results[k]['accuracy'] = acc
# results[k]['per_class_accuracy'] = cm.diagonal() / cm.sum(axis=0)
conf_mat_acc = np.zeros_like(cm, dtype=float)
# results[k]['confusion_matrix'].dtype = float
for i, row in enumerate(cm):
conf_mat_acc[i] = row / row.sum()
results[k]['confusion_matrix_accuracy'] = conf_mat_acc
return results
def visualize_confusion_matrix(cm, class_names, k):
plt.figure(figsize=(18, 18)) # Increase figure size
sns.set(font_scale=1.2) # Increase font scale
sns.heatmap(cm, annot=True, fmt='', cmap='Blues', xticklabels=class_names, yticklabels=class_names, annot_kws={"size": 12, "ha": 'center', "va": 'center'}, linewidths=.5, linecolor='black')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title(f'Predictions for k={k}')
plt.show()
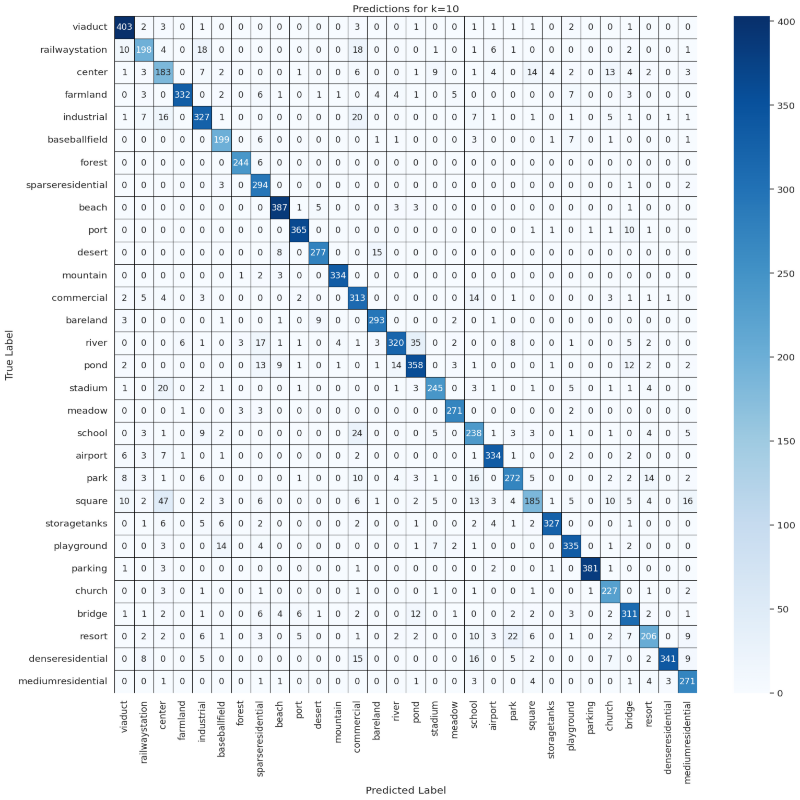
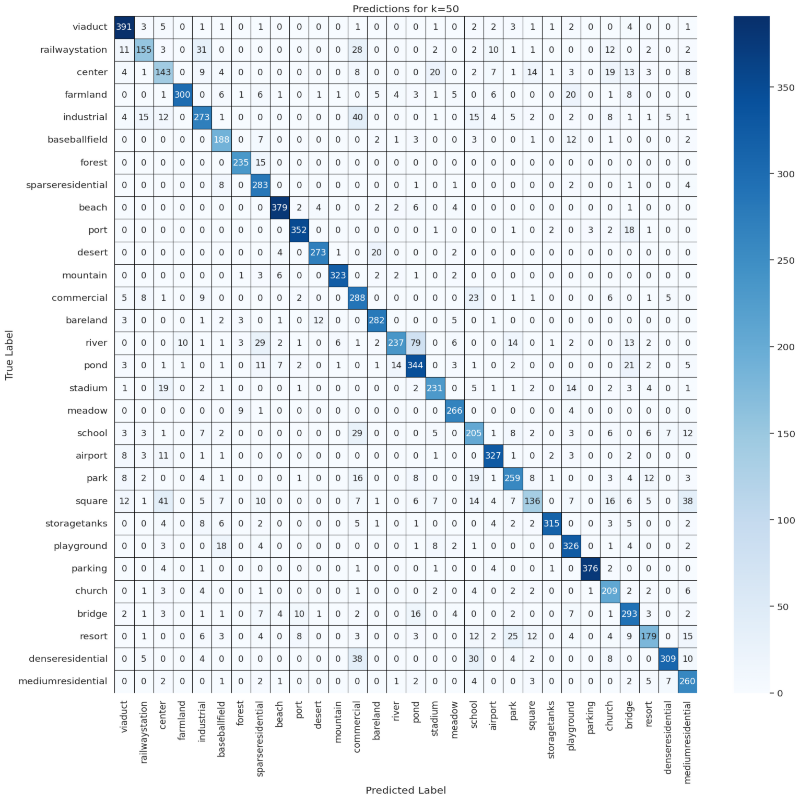
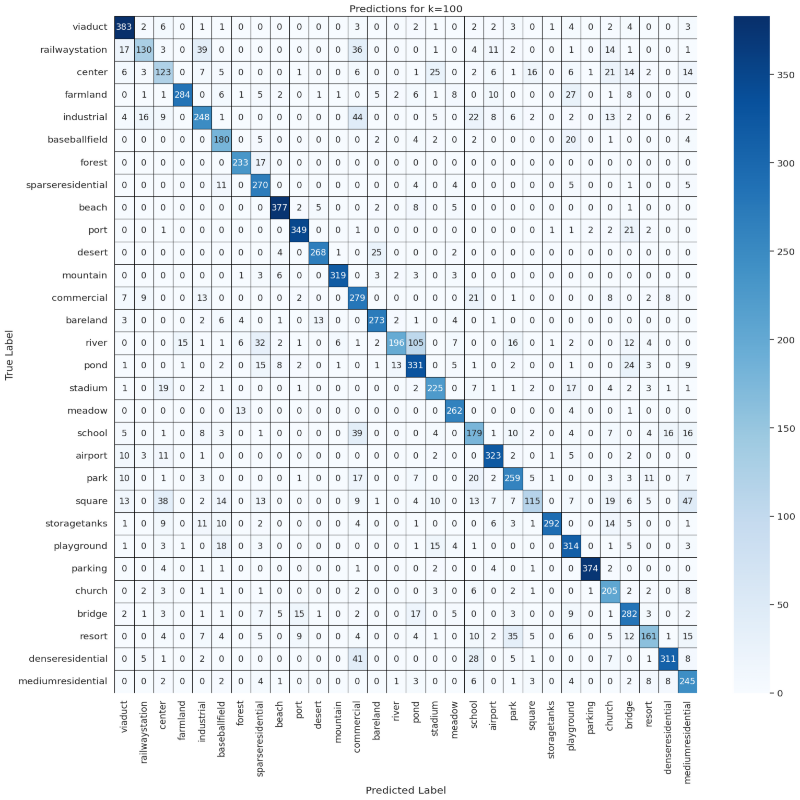
ks = [10, 50, 100]
results = compute_confusion_matrix_and_accuracy(dataset, model, device, features, labels, ks)
Accuracies Confusion Matrix
for k in ks:
visualize_confusion_matrix(np.round(results[k]['confusion_matrix_accuracy'], 2), classes, k)
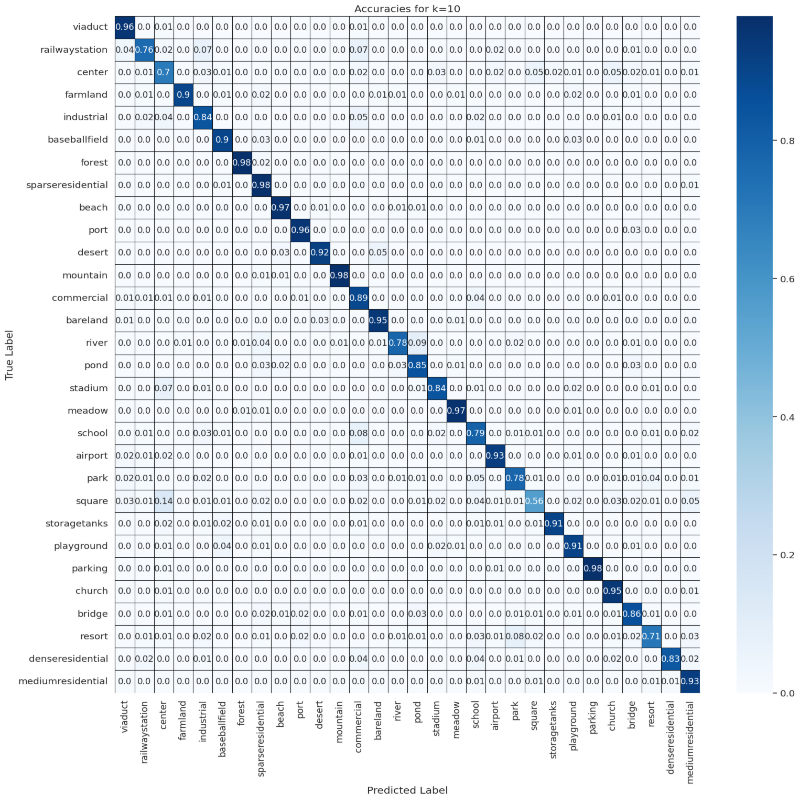
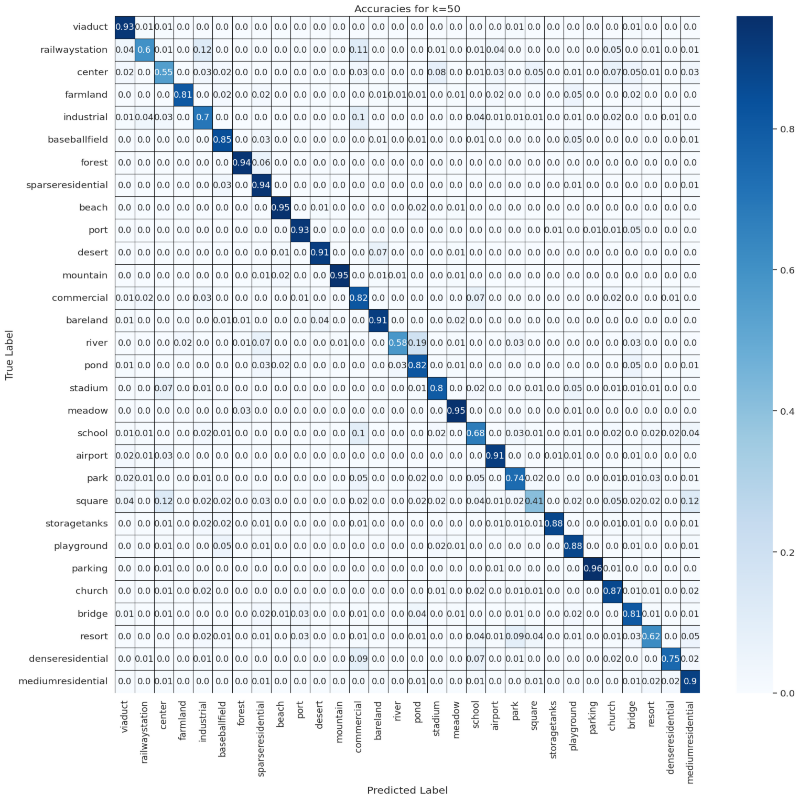
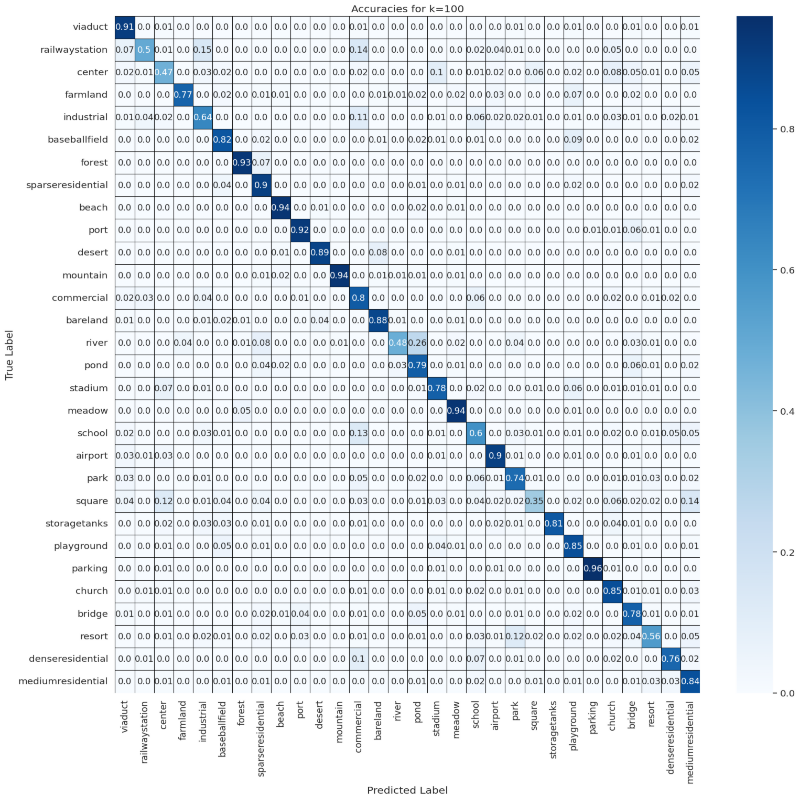
Predictions Confusion Matrix
for k in ks:
visualize_confusion_matrix(results[k]['confusion_matrix'], classes, k)